欢迎使用CSDN-markdown编辑器
本文共 747 字,大约阅读时间需要 2 分钟。
Hadoop HDFS实践攻略
理论部分:
- HDFS 基本原理
- 文件读取、写入机制
- 元数据管理思路
实践部分:
- 安装实践环境
- Shell 命令行操作方式
- Java API操作方式
HDFS基本原理
1. HDFS的解决思路
HDFS(Hadoop Distribute File System)是一个分布式文件系统,是Hadoop的重要成员。
HDFS是个抽象层,底层依赖很多独立的服务器,对外提供统一的文件管理功能,对于用户来讲,感觉就像在操作一台机器,感受不到HDFS下面的多台服务器。
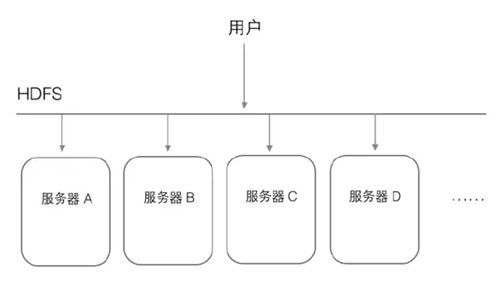
HDFS首先会把这个文件进行分割,例如分为4块,然后分别放到不同服务器上。
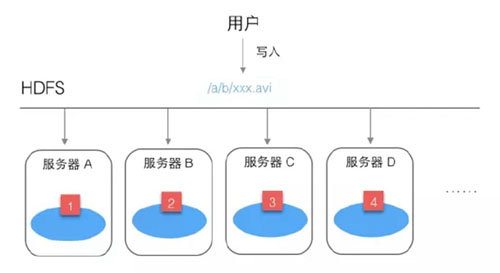
这样做有个好处,不怕文件太大,并且读文件的压力不会全部集中在一台服务器上。但如果某台服务器坏了,文件就读不全了。
HDFS为保证文件可靠性,会把每个文件块进行多个备份: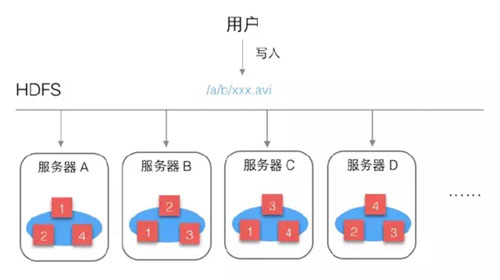
这样文件的可靠性就大大增强了,即使某个服务器坏了,也可以完整读取文件。
同时还带来一个很大的好处,就是增加了文件的并发访问能力,比如多个用户读取这个文件时,都要读块1,HDFS可以根据服务器的繁忙程度,选择从那台服务器读块11. 元数据的管理
HDFS中存了哪些文件?
文件被分成了哪些块? 每个块被放在哪台服务器上? …… 这些都叫做元数据,这些元数据被抽象为一个目录树,记录了这些复杂的对应关系。这些元数据由一个单独的模块进行管理,这个模块叫做NameNode。存放文件块的真实服务器叫做DataNode,所以用户访问HDFS的过程可以理解为: 用户-> HDFS -> NameNode -> DataNode3. HDFS优点
- 容量可以线性扩展
- 有副本机制,存储可靠性高,吞吐量增大
- 有了NameNode后,用户访问文件只需指定HDFS上的路径
转载地址:http://mdadi.baihongyu.com/
你可能感兴趣的文章
PHP那点小事--三元运算符
查看>>
解决国内NPM安装依赖速度慢问题
查看>>
Brackets安装及常用插件安装
查看>>
Centos 7(Linux)环境下安装PHP(编译添加)相应动态扩展模块so(以openssl.so为例)
查看>>
fastcgi_param 详解
查看>>
Nginx配置文件(nginx.conf)配置详解
查看>>
标记一下
查看>>
IP报文格式学习笔记
查看>>
autohotkey快捷键显示隐藏文件和文件扩展名
查看>>
Linux中的进程
查看>>
学习python(1)——环境与常识
查看>>
学习设计模式(3)——单例模式和类的成员函数中的静态变量的作用域
查看>>
自然计算时间复杂度杂谈
查看>>
当前主要目标和工作
查看>>
使用 Springboot 对 Kettle 进行调度开发
查看>>
如何优雅的编程,lombok你怎么这么好用
查看>>
一文看清HBase的使用场景
查看>>
解析zookeeper的工作流程
查看>>
搞定Java面试中的数据结构问题
查看>>
慢慢欣赏linux make uImage流程
查看>>